算法:外部排序 2018-10-29 程序之旅,记录 1 条评论 1832 次阅读 前几天看到一篇文章说的是外部排序,深有感触,这里总结一下。 首先,我们先提出一个问题:需要对占8G内存的数进行排序,但是计算机内容只有2G,该如何对这8个G的数进行排序,且效率比较高。 正常人的思维是先把8G分成4份2G数据进行排序,然后再把数据拼接回去。  再把2G有序子串进行子串合并。每次读取一个数,通过比较后再输出。  通过这种方法来回进行三次就能得到8G有序子串。在计算机中硬盘的读写速度比内存慢得多着多,所以这个算法明显不太合理,我们应该还可以有一个更好的方法。对其进行优化。既然在读取磁盘上会花费大量时间,那么我们可以使用多路归并的方法对其进行优化。例如之前使用的是两个子串进行两两合并,现在改成使用4个子串进行合并的方式。  这个 就是传说中的四路归并(n路归并)。虽然n的值越大,可以减少磁盘读取数据的次数,但是我们需要在n个数据中选取一个最小值,那么问题来时是不是n的值越大就越好呢?其实不然,如果n越大在内存中比对最小值的时间也就会越长,所以并不是n的值越大效率越高。那么我们该如果继续优化这个算法呢?该如何减少有序子串的总个数(n值),同时也减少读取磁盘的次数。从一开始我们就是人为的进行四等分数据,那么这个地方可以进行一些算法优化,从一开始就减少子串的总数。 办法肯定是有的,让我来简单的说说吧。我们先把8G的数据缩成12个数据,从这12个数据中取出3个到内存中,然后从内存中选出最小的那个数据放到子串p1中。之后从9个数据中读取一个进入到内存中,然后在从内存中选出一个数到p1子串中,这个数需要满足比p1子串所有的数大,且在内存尽可能的小。这样一直重复,直到内存中的数没有比p1中任意数大,p1子串存放结束,同样的进行p2子串的存放。 为了解决这个问题,我们需要用到堆排序,创建一个最小堆来帮助我们找到插入子串的目标数。已上一篇文章为例子:从12个数据中读取3个数据,构造一个最小堆,然后从堆顶选择一个数写入到子串p1中,之后再从从剩余的9个数中读取一个数,如果这个数比刚才那个写入到p1中的数大,则把这个数插入到最小堆中,重新调整最小堆结构,然后在堆顶选一个数写入到p1中。假设我们70、81、2、86、3、24、8、87、17、46、30、64这十二个数字,取三个到内存进行堆排序: 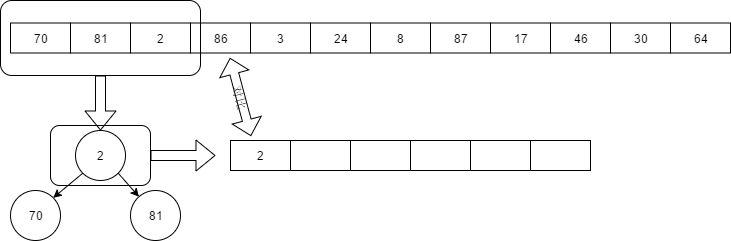 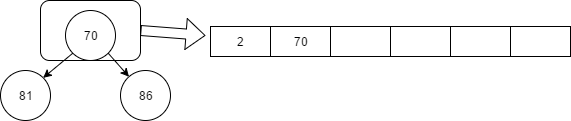 > 排到3,3不比70大,接着把剩下的81和86排序到子列中,得出p1=》2、70、81、86 按照这种节奏一直到内存中的三个数中,没有大于子串的最大数,重新排列第二个子串p2。排序过程省略,最后可以生产2个有序子串:   剩下的就是二路归并。这种方法适合要排序的数据太多,以至于内存一次性装载不下,只能通过把数据分几次的方式来排序,我们把这种方法称为外部排序。 打赏: 微信, 支付宝 标签: 算法 本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
 微信
微信 支付宝
支付宝
大神收下我膝盖