聚合、仓库与工厂 2021-09-03 程序之旅,记录 暂无评论 938 次阅读 ## 聚合、仓库与工厂 [TOC] 领域模型的最终设计可以落实到服务、实体和值对象 ### 服务 标识的是在领域对象之外的操作与行为,接收用户的请求和执行某些操作 当用户在操作界面中进行操作时,会向系统发送请求,“服务”去接收用户的这些请求,让后根据需求去执行相应的方法,所有操作都完成后,再将实体或值对象中的数据持久化到数据库中 ### 实体 通过一个唯一标识字段来区分真实显示中的每一个个体的领域对象 ### 值对象 代表真实世界中那些一成不变的、本质性的事物,这些的领域对象叫作--值对象,例如地理坐标。 > 可变性是实体的特点,不变性是值对象的本质 要把领域模型真正的落实到程序中,除了服务、实体与值对象,还要需要有聚合、仓库和工厂的设计。 ### 聚合 > 聚合表达的是真实世界中整体与部分的关系,例如表单与表单的明细;订单与订单的明细。所谓的整体与部分的关系,就是当整体不存在时,部分就变得没有了意义。 #### 聚合根--外部访问的唯一入口 聚合根--外部访问的唯一入口:外部程序不能跳过整体去操作部分,对部分的操作都必须通过整体。这样的设计有效性是有前提条件。例如:订单的新增与修改,聚合是有效的,但是对于统计销量,查询订单的趋势占比,需要用到大量的订单明细作为基础汇总,如果都是通过订单的整体查询,那么就会导致查询效率低下。所以另一方面也说明了,领域模型适合增删改,不适合分析查询。 PS:在一个系统中,增删改的业务可以采用领域驱动的设计,但在非增删改的分析汇总场景中,直接 SQL 查询。 通过聚合的设计,可以真实地反应现实世界的状况,提高软件设计的质量,有效降低日后变更的成本。要想真正的落实聚合的设计概念,还需要两个组件--仓库与工厂。 ### 仓库 举例:现在创建一个订单,订单中包含了多条订单明细,并将它们做成一个聚合。 在过去的设计中,我们通常是使用订单 DAO 与订单明细 DAO 去完成数据库的保存,由订单 Service 去添加事务这样的设计,没有聚合、缺乏封装,不利于日后的维护。 假如采用领域驱动设计,通常就会实现一个仓库(Repository) 去完成对数据库的访问。 ##### 仓库与数据访问层(DAO)的区别 数据访问层就是对数据库中某个表的访问,比如订单有订单 DAO,订单明细有订单明细的 DAO。 如果在查询订单的时候需要显示用户名称,这里会怎么设计。很容易我们会想到直接做一个订单对象,并在该对象里添加“用户名称”,通过数据访问层中的 SQL 去 join 用户表,从而达到查找用户的名称信息。这个时候你会发现在系统中会存在两个或多个订单对象,新添加的对象与领域模型的对象有较大的差别,随着系统慢慢变得复杂,订单的新对象会变得越来越多而且复杂,变更与修改会变得越来越麻烦。 这个时候,如果使用的是领域模型的仓库组件,他会是这样设计,在订单对象 Order 中添加一个用户主键和用户对象的引用,这样查找出来的就是用户的整体信息,在订单创建的时候需要给用户主键与订单明细的集合赋值,这样就实现了领域模型的聚合关系。 ```java class Order { private int customer_id; private Customer customer; // 订单明细集合 private Set<OrderItem> orderItems; } ``` > 对象间的关系是否是聚合关系,它们在保存的时候是有差别的。例如:保存订单时,需要操作订单明细表,但是不会操作用户表,只是保存用户的主键。通过订单仓库的封装,只需要在邻域对象建模的时候设定对象间的关系,即将其设定为“聚合”。 在查询订单时,通过主键把用户信息查询出来的操作,我们称之为装载(Load)--通过主键 ID 去查询某条记录。 在邻域模型中的仓库中查询,不会去使用 join 去装载引用的对象,举例:订单仓库在查询订单时,只是简单地查询订单表,查询到该订单后,将其封装在订单对象中,通过查询补填用户对象、订单明细对象,通过补填后,会得到一个用户对象、多个订单明细对象,需要将它们装配到订单对象中。 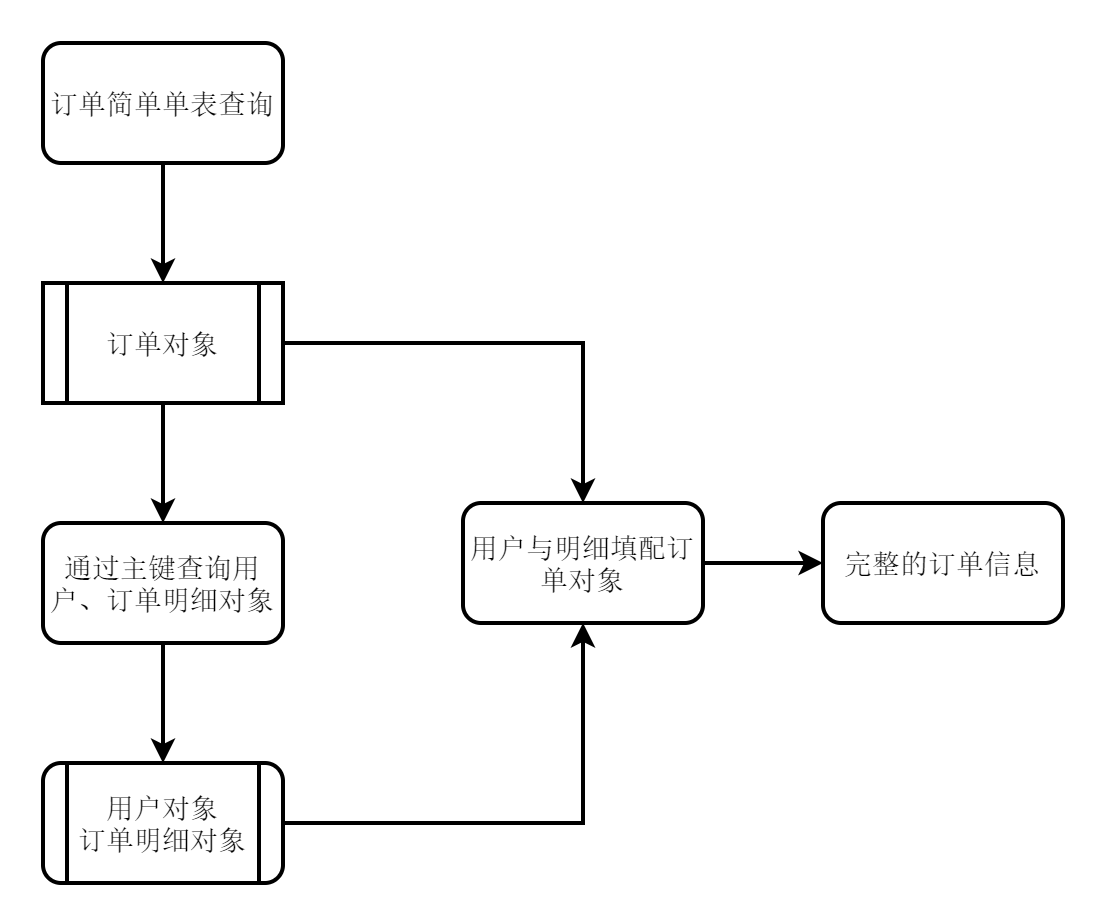 > 这一些列的创建装配工作就交给了领域模型的另一个组件--工厂 ### 工厂 在设计模式中,将被调方设计成一个接口下的多个实现,将这些实现放入工厂中,工厂负责通过 key 值找到对应的`实现类`,创建出来,返回给调用方,从而降低了调用方与被调方的耦合度。而领域模型中的工厂与之相同的都是创建对象,领域模型中的工厂是通过装配创建领域对象,是邻域对象的起点。例如: - 订单仓库将任务交给订单工厂,订单工厂分别调用订单 DAO、订单明细 DAO 与用户 DAO 去进行查询。 - 将订单明细对象与用户对象,分别 set 到订单对象的“订单明细”与“用户”属性中。 - 订单工厂将装配好的订单对象返回给订单仓库。 > 仓库的实现其实有两种,一种是数据库的持久化,另一种是缓存。当用户程序通过 id 去获取某个领域对象时,仓库会通过这个 id 先到缓存中进行查找,如果找不到,则通知工厂,工厂调用 DAO 去数据库查找并装配。 当是已查询条件的方式去查询订单步骤会有点不一样,例如: - 订单仓库先通过订单 DAO 去查询订单表 - 订单表 DAO 查询订单表后,会进行一个分页,将某一页的数据返回给订单仓库 - 订单仓库会将查询结果交给订单工厂,去补填对应的用户与订单明细,完成相应的装配,将装配好的订单对象集合返回给仓库 ### 总结 通过仓库与工厂,对原有的 DAO 进行了一层封装,在保存、装载、查询等操作中,加入聚合、装配等操作,并将这些操作封装起来,对上层的客户程序屏蔽,技术门槛降低,维护也变得简单了。 PS:这里还有个疑问,在条件查询的过程中,过滤条件中有订单明细的过滤条件,但是订单仓库没有通过 join 操作去查询分页,该如何对订单明细进行条件查询。 答:可以通过 EXISTS 进行条件判断,如果是分库,可以适当的增加冗余,或者是使用`宽表`的方式解决查询的问题。当系统要在某些查询模块进行订单查询时,可能对各个字段都需要进行过滤查询。这时就不再采用数据补填的方式,而是利用 NoSQL 的特性,采用“宽表”的设计。按照这种设计思路,当系统通过读写分离从生产库批量导入查询库时,提前进行 join 操作,然后将 join 以后的数据,直接写入查询库的一个表中。由于这个表比一般的表字段更多,因此被称为“宽表 打赏: 微信, 支付宝 标签: DDD 本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
 微信
微信 支付宝
支付宝